 SszgwDk
SszgwDkCMU15-445 Fall 2023 Project 3
Project 3 Query Execution的任务是实现BusTub执行SQL命令的组件。主要分为:
- 执行SQL查询的算子
- 优化规则的实现
Project 3 的难点在于读代码,理解查询引擎的原理,弄懂了之后具体实现起来并不难。
bustub的SQL引擎解析
墙裂推荐下面这篇文章
做个数据库:2022 CMU15-445 Project3 Query Execution - 知乎 (zhihu.com)
bustub的表结构
这里引用一下 做个数据库:2022 CMU15-445 Project3 Query Execution中的图
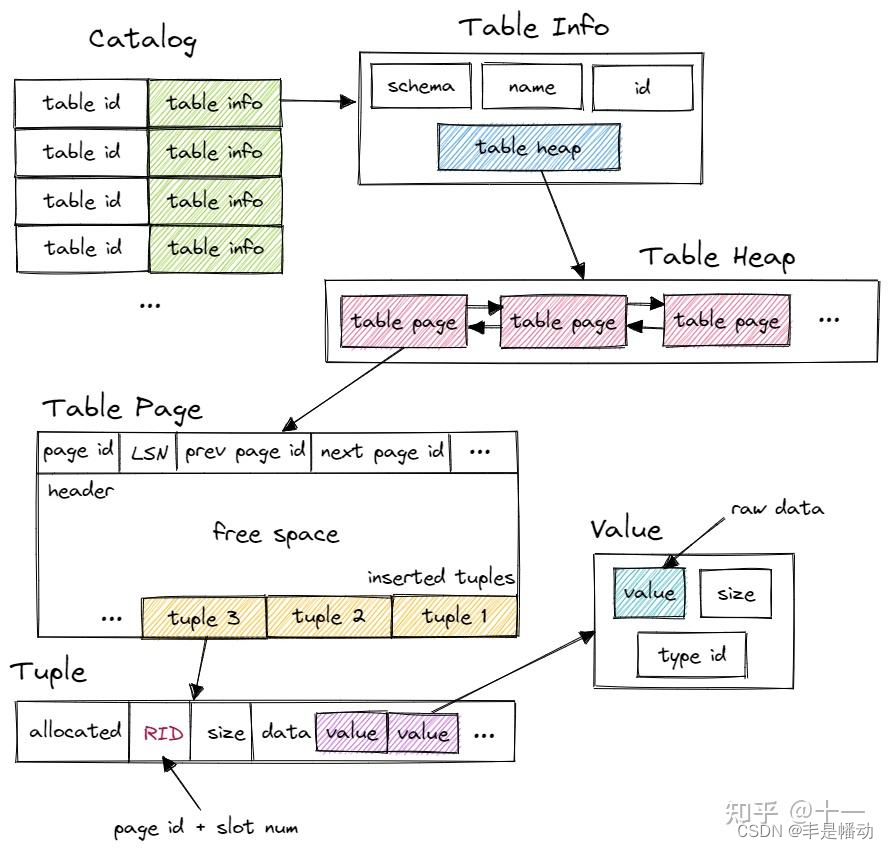
首先,Bustub 有一个 Catalog。Catalog 维护了几张 hashmap,保存了 table id 和 table name 到 table info 的映射关系。table id 由 Catalog 在新建 table 时自动分配,table name 则由用户指定。这里的 table info 包含了一张 table 信息,有 schema、name、id 和指向 table heap 的指针。系统的其他部分想要访问一张 table 时,先使用 name 或 id 从 Catalog 得到 table info,再访问 table info 中的 table heap。
table heap 是管理 table 数据的结构,包含 table 相关操作。table heap 可能由多个 table page 组成,仅保存其第一个 table page 的 page id。需要访问某个 table page 时,通过 page id 经由 buffer pool 访问。
table page 是实际存储 table 数据的结构,当需要新增 tuple 时,table heap 会找到当前属于自己的最后一张 table page,尝试插入,若最后一张 table page 已满,则新建一张 table page 插入 tuple。table page 低地址存放 header,tuple 从高地址也就是 table page 尾部开始插入。
tuple 对应数据表中的一行数据。每个 tuple 都由 RID 唯一标识。RID 由 page id + slot num 构成。tuple 由 value 组成,value 的个数和类型由 table info 中的 schema 指定。value 则是某个字段具体的值,value 本身还保存了类型信息。
火山模型/迭代模型
本 Project 中的查询算子采用 iterator query processing model,也就是火山模型进行实现。
每个算子会实现自己的Next() 方法来迭代式获取下一个 tuple。当Next() 函数被调用时,算子可能返回
- 单一的 tuple
- 没有更多的 tuple
在 BusTub 的实现中, Next函数还会额外返回一个 record identifier (RID),用于唯一标识一个 tuple。所有的算子都在工厂类 executor_factory.cpp 中被创建。
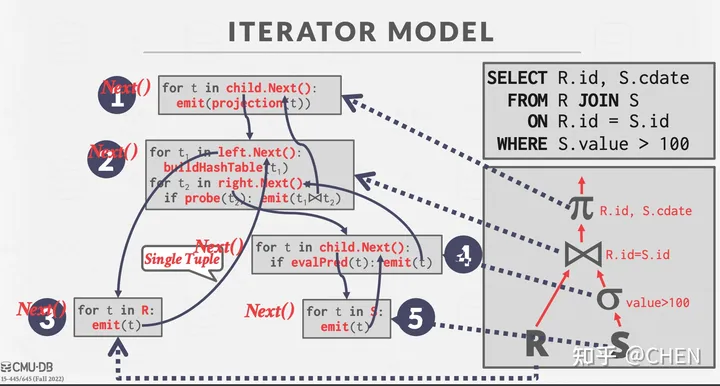
注意有很多算子属于 pipeline breakers,它会阻塞直到孩子发出所有的元组。我在实现的时候将这个阻塞的过程放在了“Init”方法中。由于算子可能会被多次调用“Init”来重复使用,在实现的时候可以引入一些标记为进行判断,避免多次阻塞影响性能。
样例算子代码解析
Bustub提供了几个样例算子的实现可供我们参考学习。
Project算子
Project算子的构造函数如下
| |
AbstractExecutor
AbstractExecutor是一个抽象类型,主要的成员是一个ExecutorContext指针。ExecutorContext保存了一个算子运行所需的所有上下文,主要成员包括:
- 事务上下文
Transaction -
Catalog:提供有关访问、修改表的API -
BufferPoolManager:project2的内容,无需多盐 -
TransactionManager:暂时应该不用管 -
LockManager:也是事务相关,暂时不管 -
check_exec_set_:用于优化任务 -
checkOptions:检查的选项,用于优化任务 -
is_delete_:23fall已经不使用了
它提供的API大多是返回私有成员的指针,需要重点关注和使用Catalog、BufferPoolManager提供的API。后续P4中Transaction和TransactionManager也非常关键。
ProjectPlanNode
其中保存了该算子的执行计划,构造函数如下:
| |
它继承了抽象类AbstractPlanNode,先来看一下它,主要有两个成员:
-
output_schema_:一个SchemaRef类型(Ref的含义就是std::shared_ptr)的对象,标明输出结果包含哪些列 -
children_:这个 plan node的孩子节点
整个AbstractPlanNode提供的也是非常基础的API,例如:
| |
ProjectionPlanNode类除了继承了AbstractPlanNode,还增加一个成员std::vector<AbstractExpressionRef> expressions_;
来看看它有啥用,字面意思理解好像就是表达式。
首先项目文档有关于它的描述:
BusTub 中的 Expression 定义如下:
-
ColumnValueExpression: directly places a column of the child executor to the output. The syntax#0.0 means the first column in the first child. You will see something like#0.0 = #1.0 in a plan for joins.-
ConstantExpression: represents a constant value (e.g.,1).-
ArithmeticExpression: a tree representing an arithmetic computation. For example,1 + 2 would be represented by anArithmeticExpression with twoConstantExpression (1 and2) as children.
实际很好理解:列值表达式、常量表达式、数学表达式
不论是哪个类型,最重要关注的都是它的Evaluate和EvaluateJoin接口。以列值表达式为例:
| |
很容易理解,就是执行该表达式并返回结果。(列值表达式中GetValue就代表取某一列的值)
Project算子的API实现
根据上面提到的火山模型,各个算子都需要实现Init和Next两个API,Project算子的实现如下:
| |
Init当中需要注意执行一下子算子的Init。
Next的逻辑也十分简单:就是先求子节点得到child_tuple,然后在执行本节点的计划(执行表达式),然后将执行结果返回。
Task#1:Access Method Executors
seqscan
由于每次获取一个tuple,因此要在算子增加一个迭代器成员,记录当前扫描到的位置。
| |
注意next中每次成功获取一个Tuple,就返回成功。
但是要注意判定两个条件:
- 当前tuple没有被删除,需要检查
TupleMeta中的is_deleted_ - 如果有
filter_predicate(过滤谓词,就是过滤的条件),需要通过Evaluate检查是否满足该条件。(使用方式可以参考Filter算子中的Next实现)
filter_predicate都是一个Expression,所有表达式都是通过Evaluate来进行判断和运算。表达式类型很多,有常量表达式,列值表达式,逻辑表达式,比较表达式等等,需要重点理解。
Insert、Update、Delete
Insert、Update和Delete三个算子需要首先关注的是它们均只执行一次,因此要在类成员中加入一个标记。
| |
构造函数注意给plan_和child_executor_都赋值。
由于存在子节点,Init函数需要调用子节点的Init函数。
| |
Insert算子的任务主要有两个:
- 将Tuple插入目标表
- 如果表上存在索引,在这些索引中更新该Tuple的信息
具体实现:
循环通过调用子节点的Next获取将被插入的记录。调用InsertTuple插入记录,返回值为新插入记录的rid。
在bustub中索引中存储的是对应记录的rid,因此要在目标表中所有的索引表中插入该条记录的索引信息。框架代码中提供了KeyFromTuple来提取一个tuple在索引中的key,需要注意参数分别是:整个表的Schema(包含所有属性/列)、索引key的Schema、索引key的属性列表。
同时由文档和注释可知,Next返回的Tuple(出参)是Insert操作影响的行数,实际上就是统计插入的Tuple个数。
| |
Update算子的思路大致与Insert相同,不过要先删除旧的记录、再插入更新后的记录。删除通过table_info_->table_->UpdateTupleMeta(TupleMeta{0, true}, rid)将对应的tuple标记为is_delete_=true。
如何获取更新后的Tuple?通过Update算子的执行计划plan_中的表达式获取。
| |
然后调用Insert接口插入新记录。接下来同样需要更新索引表中的对应索引,因为更新后的记录有了新的rid。这个比较简单,也是先删除后插入。
Delete算子略。
IndexScan
索引扫描,即通过查找索引执行扫描操作,仅适用于匹配单个列的值(例如Select * from t1 where x = 1)。Bustub 对哈希索引做了很强的约束,只会对单个列建立索引,也不会插入重复的值。所以,从 IndexScanExecutor 中只可以获取一个或零个 tuple。
一个关键信息是:IndexScanExecutor的执行计划plan_,也就是IndexScanPlanNode成员,包含一个const ConstantValueExpression *pred_key_;,代表目标列的目标值。还包含了index_oid_,代表所需索引表的id。
在init中先通过index_oid_获取索引表hash_table,再解析出pred_key_及其值key_val,构建一个Tupleindex_key,调用hash_table的ScanKey接口,得到target_rids_存储在算子自己的内存当中。
Next的实现较为简单,就是提取target_rids_中第一个rid,获取对应的Tuple返回即可,如果target_rids为空或tuple的is_deleted == true,返回false。另外,同Insert,IndexScan算子只执行一次,因此要在类成员中加入一个标记。
将Seqscan优化成Indexscan
实现将SeqScanPlanNode优化为IndexScanPlanNode的优化器规则
函数原型:将原来的SeqScanPlanNode替换成优化后的执行计划节点(有可能不满足优化的条件导致没有变化)
| |
需要重点关注转化的条件:仅当谓词中的索引列上有一个相等性测试时,才需要支持此优化器规则(来自的项目文档的翻译)
实现流程如下:
首先对所有子节点递归调用应用这一优化
将优化后的子节点重新赋值给当前节点
auto optimized_plan = plan->CloneWithChildren(std::move(optimized_children));如果当前节点类型为
SeqScan获取当前节点的谓词
predicate(where 子句)检查是否满足 seqscan -> indexscan 转化的条件:
- 表中有索引
-
predicate不是逻辑运算,而是比较运算:auto cmp_expr = std::dynamic_pointer_cast<ComparisonExpression>(predicate); - 必须为等值比较(即WHERE v1 = 1)
- 存在等值比较对应的列上的索引
如果满足,提取indexscan所需的prev_key:
auto pred_key = std::dynamic_pointer_cast<ConstantValueExpression>(cmp_expr->GetChildAt(1));,然后构造一个IndexScanPlanNode返回
不满足转化条件,直接返回
optimized_plan
Task#2:Aggregation & Join Executors
Aggregation聚合
Aggregation算子对每个输入Group计算一个聚合函数,它只有一个孩子。
一些Aggregation的例子:
| |
AggregationExecutor 需要先从子执行器中获取所有数据,然后对这些数据进行分组和聚合操作,最后将结果输出,而这个过程必须在init函数中完成。
即文档中提到的pipeline breaker。
聚合操作不能简单地按行(tuple-by-tuple)从其子节点接收数据,然后逐行输出结果。相反,聚合操作需要先从其子节点获取所有相关的数据,完成整个聚合计算过程(例如计算总和、平均值、最小/最大值等),然后才能产生输出结果。
实现聚合的一个常见的策略是维护一个哈希表,哈希表的key为Group-by子句对应的列值(对应一个分组),value为一个结果向量(因为可能同时有多个聚合函数)。该项目也是采用该思路。
框架代码已经完成了哈希表的核心数据结构,key和val都是一个std::vector<Value>,如下:
| |
我们需要封装一个SimpleAggregationHashTable用于统计聚合结果,核心数据结构就是上面的ht_。它已经提供了一个初始化聚合值API,即除了countstar操作,其他聚合操作的初始值都是null。
| |
我们需要实现CombineAggregateValues,功能是当一个输入到达时更新聚合值。几个聚合运算都非常简单,需要注意除了countstar,其他运算都不用考虑null值。
| |
接下来需要实现InsertCombine,即插入一个AggregateKey和AggregateValue。这是一个很关键的API。用于在哈希表中插入一个聚合键,同时更新聚合函数结果。
| |
接着实现AggregationExecutor,即聚合算子,首先根据注释,增加两个成员,一个是上面的哈希表,一个是其上的迭代器,用于记录当前位置。
| |
根据上面的分析,聚合算子的Init函数要先从子节点获取所有相关的数据,完成整个聚合计算的过程,计算结果记录在哈希表中,Next通过迭代器返回结果。
因此,Init的执行流程如下:
初始化子算子
创建一个
SimpleAggregationHashTable如果grouby子句为空,则在哈希表插入一个空的key,并初始化对应的val
循环执行完子算子(pipeline breaker):对每一个tuple
- 通过
MakeAggregateKey和MakeAggregateValue构建聚合key和val - 调用上面的
InsertCombine插入并更新聚合值
- 通过
聚合完毕,构建iter(因为可能同时有多个聚合函数)
Next函数则是通过上面构建的iter聚合的结果,每次返回一个结果。需要注意的是返回的结果形式,文档中有一句话指明了这一点。
The output schema consists of the group-by columns followed by the aggregation columns.
即聚合键中的所有列+聚合值的所有列。
NestedLoopJoin
目前只要实现InnerJoin和LeftJoin:
- InnerJoin:两个表中都有
- LeftJoin:左表的所有记录,右表中没有的取NULL
一次性讲清楚INNER JOIN、LEFT JOIN、RIGHT JOIN的区别和用法详解-CSDN博客
NestedLoopJoin的原理很简单,就是通过遍历获得匹配的行。
在本项目中,遍历是通过left_executor_->Next和right_executor_->Next实现,通过子算子的init可以将指针重新置于表的起始位置。
对于InnerJoin和LeftJoin,都是外层遍历左表,内层遍历右表,但是由于每次只返回一个Tuple,所以每次结束要保留各种状态:
- 左右表当前的指针位置已经通过子算子的
Next实现了控制,只要不调用就不会变 -
bool continue_flag_:记录当前Next函数运行的状态,若为True,代表当前左表行存在,且需要继续匹配剩下的右表行**(对于左表的一行,能够匹配的右表行可能有很多个 ),此时不需要调用左算子的Next,右算子也不需要Init;**如果为False,下次调用Next时,就会遍历下一个左表行(left_executor_->Next),然后右表指针回到起点(right_executor_->Init())。
关于如何判断是否匹配,文档中已经指明,通过predicate->EvaluateJoin。
Task#3:HashJoin Executor and Optimization
HashJoin显然是比NestedLoopJoin那种多级遍历的方式更高效的Join方法,不过要满足一定的条件才行。
HashJoin Executor
根据文档,HashJoin使用的基本前提就是谓词predicate是以下形式:
<column expr> = column AND column = column AND ...
而HashJoin常见的实现就是用一个哈希表,先遍历并存储右表的所有行;然后遍历左表的所有行时,在哈希表中查找是否存在Key相等的元素,以key相等作为匹配的条件。
文档中提示可以参考上个任务聚合算子中的哈希表自定义HashJoinKey和SimpleHashJoinHashTable。其实不论是聚合key和聚合value,主要成员都是std::vector<Value>,所以HashJoinKey也是一样的。注意为了能够让HashJoinKey作为std::unordered_map的key,要在其上自定义实现std::hash。
| |
SimpleHashJoinHashTable的实现则更为简单,定义插入、查询的接口即可。
除此之外,还要在算子中定义获取Key的方法,同样参照聚合算子中获取聚合键的实现(MakeAggregateKey),这里要区分LeftJoinKey和RightJoinKey。
Init
根据之前提到HashJoin的实现方法,Init中要获取并遍历右表的所有行,构建一个哈希表。
Next
Next的实现与NestedLoopJoin的思路几乎完全一致,区别主要在于不需要遍历右表了,只需要遍历左表获取LeftTuple,然后每次直接从hash表中查询是否有匹配上的RightTuple。
查询得到的结果是一个向量,意味着可能匹配上了多个右表行(多个RightTuple),且由于每次只返回一个Tuple,因此要在算子中记录(增加两个私有成员)当前匹配上的右表向量和一个迭代器right_tuple_iter_(用于记录位置),同时也要使用一个continue_flag_标记。
另外注意当在哈希表中没办法找到与LeftTuple匹配的RightTuple时,表明右表中不存在匹配的行,要对这种情况进行检查并分情况处理:
- 当Join类型为LeftJoin时,要返回一个结合NULL的Tuple。
- 否则,进行往下遍历下一个
LeftTuple。
OptimizeNLJAsHashJoin
将NestedLoopJoin优化为HashJoin,大体思路与之前将SeqScan优化为IndexScan类似:
- 对所有子节点递归应用这一优化
- 检查当前plan的
predicate是否满足优化的条件 - 如果满足,准备参数并创建优化后的PlanNode
核心在于检查是否满足优化条件,主要通过dynamic_cast和predicate类型来判定。
这个优化主要检查predicate是否满足:
<column expr> = column AND column = column AND ...
由于可能有多个AND子句,递归检查是一个很好的方法。
Task#4:Sort + Limit Executors + Window Functions + Top-N Optimization
本任务中需要实现的几个算子都是需要在init阶段就获取所有子算子的输出结果(pipeline breaker),然后进行操作。
Sort
Sort算子的Init和Next思路简单,init获取子算子的所有Tuple后根据order by子句对tuple进行排序。
重点是自定义排序规则,当存在多个order by子句时,排在前面的order by优先级更高,因此只有靠前的order by子句计算结果都相等,才会往后计算下一个order by。
limit
更简单,在init中最多只获取limit个子算子中的Tuple。
TopN
当既有sort操作又有limit限制时,使用TopN算法(即用一个堆维护前limit个数据,std::priority_queue)显然效率更高。
Sortlimit优化为TopN
由于limit和sort都只有一个child_executor,所以很好判断。若当前节点为limit节点,且其子节点为sort节点,此时满足优化条件,将其转化为一个topn算子。
注意:构建TopN节点时,传入的子节点child_executor应该为sort节点的child,而不是limit节点的child,否则传入了sort作为topn的子节点,相当于多排了一遍序,没有任何优化。
Window Functions窗口函数
前置知识学习
【MySQL】窗口函数详解(概念+练习+实战)_mysql 窗口函数-CSDN博客
窗口函数语法
| |
通常,窗口函数由三个部分组成:partition by, order by, and window frames。这三者都是可选的,因此这些功能的多种组合使窗口功能一开始令人生畏。
但是,窗口函数的概念模型有助于使其更易于理解. 概念模型如下:
- 根据 partition by 子句中的条件拆分数据。
- 然后,在每个分区中,按 order by 子句顺序排序。
- 然后,在每个分区(现在已排序)中,循环访问每个元组。 对于每个元组,我们计算该元组的帧的边界条件。每个帧都有一个开始和结束(由window frames子句指定)。window 函数是在每一帧的元组上计算的,我们输出我们在每一帧中计算的内容。
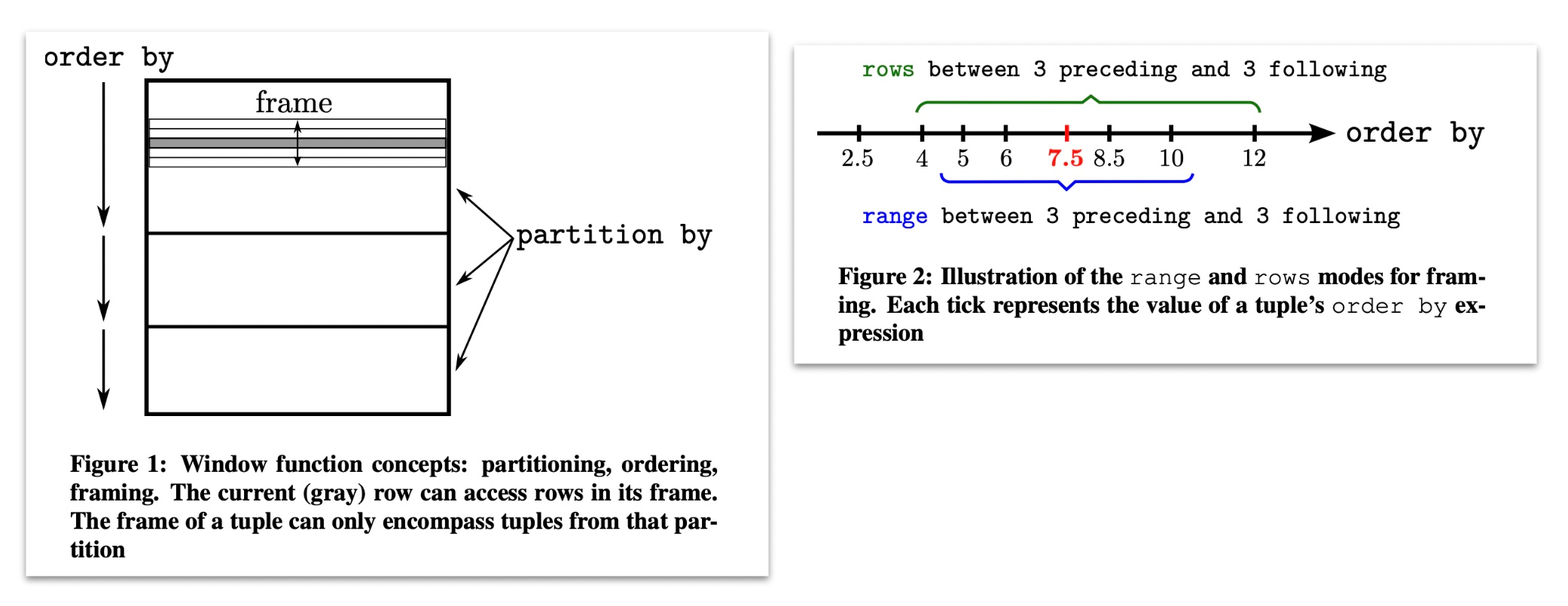
如果没有 order,聚合的窗口是第一个值到最后一个值;如果有 order,聚合的窗口的第一个值到当前值;如果有 partition,聚合只针对 partition 内
任务要求和提示
这个任务不需要处理window frames,只需要实现PARTITION BY和ORDER BY子句。BusTub保障所有在一个查询中窗口函数的ORDER BY子句都是相同的。
只要每行中的列匹配,测试用例就不会检查输出行的顺序。因此,当有ORDER BY子句时,可以在进行计算之前先对元组进行排序,并且在没有子句排序时不要更改来自子执行程序的元组的顺序
您可以通过以下步骤实现算子:
- 执行
ORDER BY子句排序Tuples - 对每个partition生成初始值
- Combine values for each partition and record the value for each row.
您可以重用sort算子中的代码来完成步骤 1,并重用聚合算子中的代码来完成步骤 2 和步骤 3。
除了之前任务实现的聚合函数,您还需要实现RANK函数。BusTub Planner确保如果存在RANK窗口函数,ORDER BY子句不为空。
算子实现
根据文档提示,需要参考aggregate算子的哈希表实现窗口函数的运算(即实现一个窗口函数哈希表SimpleWindowFunctionHashTable),同时需要参考sort算子实现order by子句排序。
首要考虑的问题是:计算窗口函数所用的哈希表的key和val如何定义?
先看WindowFunction的定义,有一个对应的function_、多个partition_by_和order_by_子句。
| |
根据窗口函数的概念模型,根据 partition by 子句中的条件拆分数据,即为key,参考aggregation算子的AggregateKey,可以发现同样适用于Windowkey。
而对于value,不同于aggregation那样可以同时运算多个聚合函数,一个窗口函数只有一个function_,因而value应为单个Value
| |
明确了key和value定义,对照aggregation算子的哈希表实现,封装SimpleWindowFunctionHashTable的GenerateInitialAggregateValue、CombineAggregateValue和InsertCombine三个接口,实现逻辑十分相似。
一处需要注意的地方是InsertCombine和CombineAggregateValue现在都会返回一个当前计算得到的Value(aggregation则是统计一个Group_by_中的所有元组),这也是由于窗口函数的特性:**“如果有 order,聚合的窗口为第一个值到当前值”。**所以在输出中一个partition_by_组中不同Tuple的对应列的值都是不同的。
为了更方便实现窗口函数算子的功能,我增加了以下两个私有成员:
-
std::vector<SimpleWindowFunctionHashTable> whts_ -
std::deque<std::vector<Value>> tuples_
窗口函数算子的Init是一个难点,文档提供了实现步骤,不过很粗略。我的具体实现步骤如下:
初始化子算子,获取子算子的所有输出
tuples。对于排序,根据文档,所有的窗口函数只支持一个order by子句,因此这里只需要找到第一个order_by子句,然后采用Sort算子中同样的排序规则即可。
接下来考虑为每个窗口函数构建哈希表,planNode当中记录了执行计划的所有输出列,并且为窗口函数的列构建了一个哈希表(
plan_->window_functions_)。对于普通数值列不做任何处理,对于窗口函数列为其构建一个哈希表,用于后续的窗口函数计算。接着对所有元组执行窗口函数:
创建一个Value向量
values遍历所有输出列:
- 如果只是单纯的数值列,不需要进行处理直接存入vector
- 如果是窗口函数列,则先构建Windowkey,接着计算要插入哈希表的Value,可通过窗口函数
function_得到对应的列值(注意对于Rank操作要特殊处理,因为是根据order_by子句排序,所以要取order_by列的值)。最后再调用哈希表的接口计算窗口函数。(此时哈希表中存的是第一个tuple到当前tuple的聚合结果,不一定是最终结果)
tuples_.emplace_back(std::move(values));
最后还有一个特殊处理,就是对于没有order_by子句的窗口函数列,需要取出哈希表中计算出的最新值,即每个partition_by_下的统计结果。
这同样是基于窗口函数的概念模型:如果没有 order,聚合的窗口是第一个值到最后一个值;如果有 order,聚合的窗口的第一个值到当前值;如果有 partition,聚合只针对 partition 内